오늘은 지난번에 알아본 find 함수를 직접 활용하여 네이버 뉴스 크롤링 예제를 진행해보겠습니다.
아마 뉴스나 주식 같이 특정 정보가 필요할 때 크롤링을 많이 하다 보니 직접 간단하게라도 경험해보는 게 도움이 되지 않을까 싶어 준비했습니다.
네이버 뉴스 크롤링하기
본격적으로 네이버 뉴스를 크롤링하기 전에, 네이버 뉴스의 특성에 관해 알아볼 필요가 있습니다.
현재 네이버 뉴스는 크게 두 가지 형태로 제공되는데요, 첫 번째는 연합뉴스 속보 페이지, 두 번째는 뉴스홈 페이지(언론사별)입니다.

오늘 연습해볼 내용은 연합뉴스 속보 페이지입니다. 뉴스홈 페이지는 최근에 리뉴얼되면서 생겼는데요, 모바일에 초점을 맞춰 반응형 웹으로 만들어져 있습니다. 여기는 좀 크롤링하기 복잡할 것 같아 쉬운 내용부터 진행하고, 나중에 기회가 된다면 다뤄보도록 하겠습니다.
크롤링을 하기 위해서는 먼저 웹사이트 분석이 필요합니다. 내가 필요한 정보가 어디에 있는지 파악하는 과정입니다.
키보드 F12 버튼을 클릭하게 되면 웹사이트의 코드를 볼 수 있습니다. 마우스를 올리면 어떤 태그가 어떤 내용을 포함하고 있는지 색상 표시로 알 수 있습니다.
참고로 저는 크롬 기준으로 작업하고 있는데, 파이어폭스, 엣지 등에서도 모두 지원하는 기능이므로 똑같이 따라 하시면 됩니다.
위와 같이 파란색 영역을 살펴보면서 본인이 필요한 정보가 담긴 태그를 찾으면 됩니다.
div 태그에서 수평선 윗부분 뉴스 내용을 찾아보니, 아래와 같이 dl 태그 내에 포함되어 있는 것을 확인할 수 있습니다. 더 자세히 살펴보면 dt태그와 dd 태그 첫 부분에 이미지를 포함한 큰 뉴스 내용이 담겨 있고, dd 태그 뒷부분에 나머지 내용이 담겨 있다는 것을 확인할 수 있습니다.
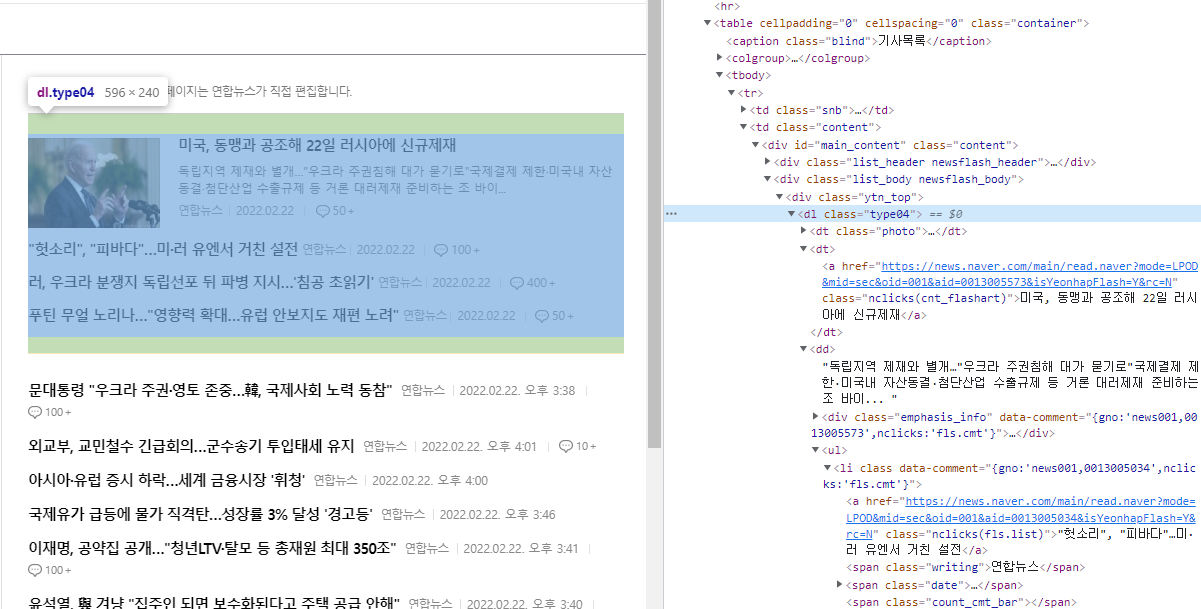
어떤 태그에 내용이 있는지 알았으니 이제 지난번에 배운 find 함수를 사용하여 쉽게 크롤링할 수 있습니다. 세세하게 특정 정보를 크롤링하려는 목적이 아니므로 간단하게 dl 태그를 통째로 찾도록 해보겠습니다. 태그 내 텍스트 전체를 가져오도록 다음과 같이 코드를 작성하였습니다.
beautifulSoup.find("dl", attrs={"class":"type04"}).get_text()
이번에는 수평선 아래쪽 내용도 크롤링해봅시다. 아까와 같이 어떤 태그에 내용이 있는지 찾아가면 되는데요, 위와는 조금 다른 구조로 되어 있는 것을 확인할 수 있습니다.
이번에는 ul 태그 내에 내용이 있습니다. 내부에 li 태그가 있고, 그 아래에 제목, 언론사, 날짜 등 정보를 담은 태그를 확인할 수 있습니다.
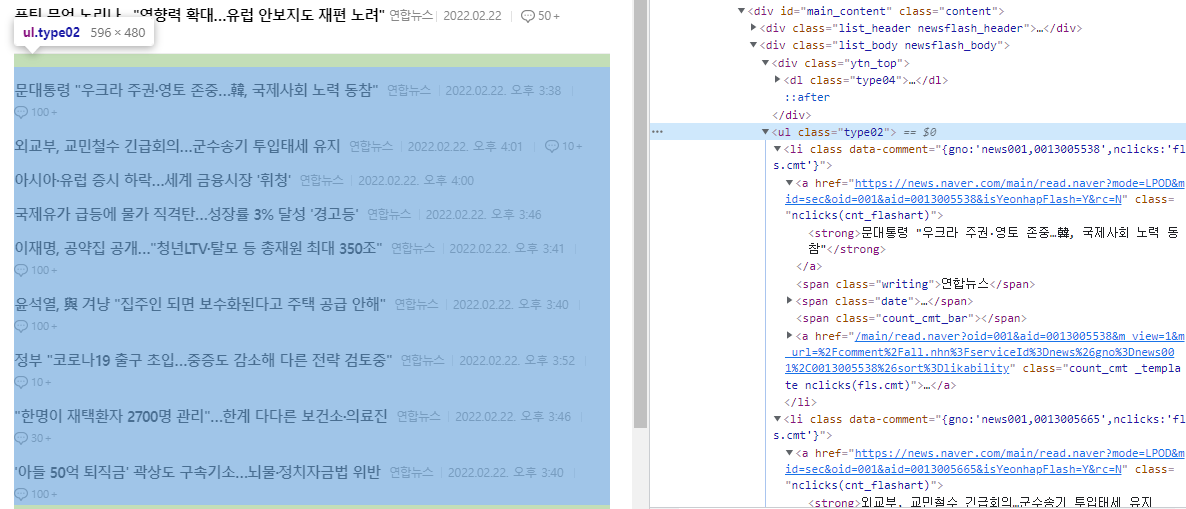
마찬가지로 간단하게 ul 태그만 가져오고, 그 안에서 텍스트 전체를 크롤링하려면 다음과 같이 코드를 작성할 수 있습니다.
beautifulSoup.find("ul", attrs={"class":"type02"}).get_text()
자 그럼 이렇게 실행하면 잘 동작할까요? 원래는 잘 동작해야 하는데, 아래와 같이 이상한 오류가 발생하는 경우도 있습니다. 이 경우는 지난번 포스팅에서 다루었던 request 오류입니다.
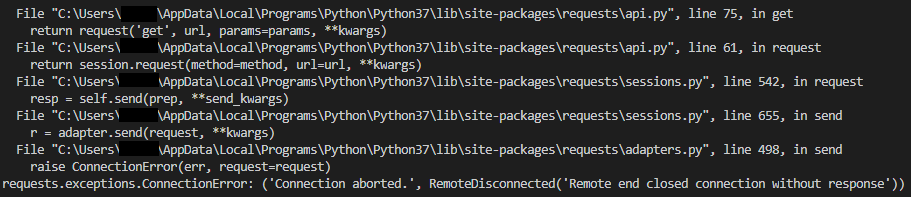
해당 내용은 아래 링크를 참고하시기 바랍니다.
https://homubee.tistory.com/19
[BeautifulSoup] #2 파이썬 웹 크롤링 네이버 오류 해결 방법
오늘은 파이썬으로 네이버 웹 크롤링 중 발생하는 오류 해결 방법에 대해 알아보겠습니다. BeautifulSoup를 활용한 강의의 연장선이지만, 파이썬 선에서 발생하는 문제입니다. 일반적으로 웹 크롤
homubee.tistory.com
이렇게 완성된 전체 코드는 다음과 같습니다.
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
# main
if __name__ == "__main__":
inputURL = "https://news.naver.com/main/list.naver?mode=LPOD&mid=sec&sid1=001&sid2=140&oid=001&isYeonhapFlash=Y"
response = requests.get(inputURL, headers=headers)
beautifulSoup = BeautifulSoup(response.content, "html.parser")
print(beautifulSoup.title.string)
print(beautifulSoup.find("dl", attrs={"class":"type04"}).get_text())
print(beautifulSoup.find("ul", attrs={"class":"type02"}).get_text())
아래와 같이 내용이 잘 출력되는 것을 확인할 수 있습니다.
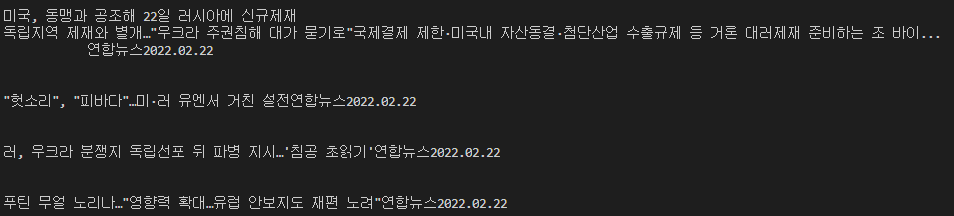

중간중간 줄바뀜이나 공백이 이상하게 출력되는 경우가 있는데, 이는 원래 텍스트 내용이 그런 것이므로 문제가 있는 것은 아닙니다. 다만, 실제로 이 데이터를 사용하려면 본인이 원하는 형태로 가공하는 과정이 필요할 것입니다.
일단 오늘은 간단하게 find 함수를 활용하는 예제이므로 그렇게 세세한 내용까지 다루지는 않겠습니다.
지난번 배운 find 함수를 활용하여 네이버 뉴스 크롤링을 해보았습니다. 아마 코드 몇 줄로 쭉쭉 크롤링이 되어서 놀라셨을 것도 같습니다.
사실 직접 복사 붙여넣기 해가면서 하기에는 너무 귀찮은 일입니다. 저도 웹 크롤링을 알기 전에는 일일이 복사 붙여넣기 하면서 작업한 경험이 있는데, 지금 다시 생각해보면 너무 시간이 아깝고 힘들었습니다. 파이썬은 언어도 쉽고 크롤링도 어렵지 않으니, 이런 작업은 꼭 공부해서 자동화를 시도해보시기 바랍니다.
직접 조사해서 작성하는 글이다 보니 일부 정확하지 않은 정보가 포함되어 있을 수 있습니다.
궁금한 사항이나 잘못된 내용이 있으면 댓글로 알려주세요~
구독과 좋아요, 환영합니다!
'웹 > 크롤링' 카테고리의 다른 글
| [BeautifulSoup] #3 find 함수 사용법 (0) | 2022.02.16 |
|---|---|
| [BeautifulSoup] #2 파이썬 웹 크롤링 네이버 오류 해결 방법 (0) | 2022.02.12 |
| [BeautifulSoup] #1 파이썬 웹 크롤링, 웹사이트 제목 크롤링하기 (0) | 2022.01.26 |